Model extraction, LLM abuse, steganography, and covert learning
part 1
-Ari Karchmer; October 2023
Introduction
Consider LLM chatbots like OpenAI's ChatGPT or Anthropic's Claude. Could a prolonged interaction with ChatGPT be sufficient to "clone" it? In other words, could someone engage with Claude extensively enough to develop "Claudio," a reasonable impersonation of Claude?
In a model extraction attack, an adversary maliciously probes an interface to a machine learning (ML) model in an attempt to extract the ML model itself. Model extraction was first introduced as a risk by Tramer et al. [TZJ+16] at USENIX '16.
Besides impersonating chatbots, having an ML model stolen poses significant risks in any machine learning as a service (MLaaS) scenario. Let's highlight two main concerns that emphasize why the model extraction scenario is critical.
- Intellectual Property Concerns. Often, an ML model is considered confidential and represents valuable intellectual property that should remain proprietary. In extreme cases, such as modern Large Language Models (LLMs), the model in the wrong hands could lead to significant problems.
- Security and Privacy Concerns. Preventing model extraction enhances security and privacy. For instance, adversarial example attacks become easier once the model is known rather than being a black-box (see e.g., [CJM20] and references therein). The same holds true for model inversion attacks, where adversaries obtain information about the data used to train the model.
Defending against model extraction
Clearly, preventing model extraction is important. Understanding how to defend against model extraction has been extensively studied in academic literature (see e.g., [KMAM18], [TZJ+16], [CCG+20], [JMAM19], [PGKS21]).
Most model extraction defenses (MEDs) in the literature fall into two categories:
- Noisy Responses. The first type aims to limit the amount of information revealed by each client query. One intuitive proposal for this defense is to add independent noise, meaning the model may respond incorrectly with some probability.
- Observational Model Extraction Defenses (OMEDs). The second type aims to identify "benign" clients, who seek to obtain predictions without attempting to extract the model, and "adverse" clients, which aim to extract the model. To differentiate between the two, the defense observes client behavior before making a decision. This approach does not alter the ML model itself.
In this blog post, we will not focus on noisy response defenses, as they inherently sacrifice the predictive accuracy of the ML model. Generally, defenses involve balancing security against model extraction with maintaining model accuracy. The noisy response defense significantly compromises accuracy, making it unsuitable for many critical ML applications such as autonomous driving, medical diagnosis, or malware detection.
OMEDs
Observational Model Extraction Defenses (OMEDs), on the other hand, preserve accuracy entirely since they do not modify the underlying model.
A common implementation of an observational defense involves a "monitor" that analyzes a batch of client requests to compute a statistic measuring the likelihood of adversarial behavior. The goal is to reject a client's requests if their behavior surpasses a certain threshold based on this statistic. Examples of such implementations can be found in [KMAM18], [JMAM19], and [PGKS21].
Essentially, observational defenses aim to control the distribution of client queries. They classify clients that deviate from acceptable distributions as adverse and subsequently restrict their access to the model. See Figure 1 below for a depiction of this setting.
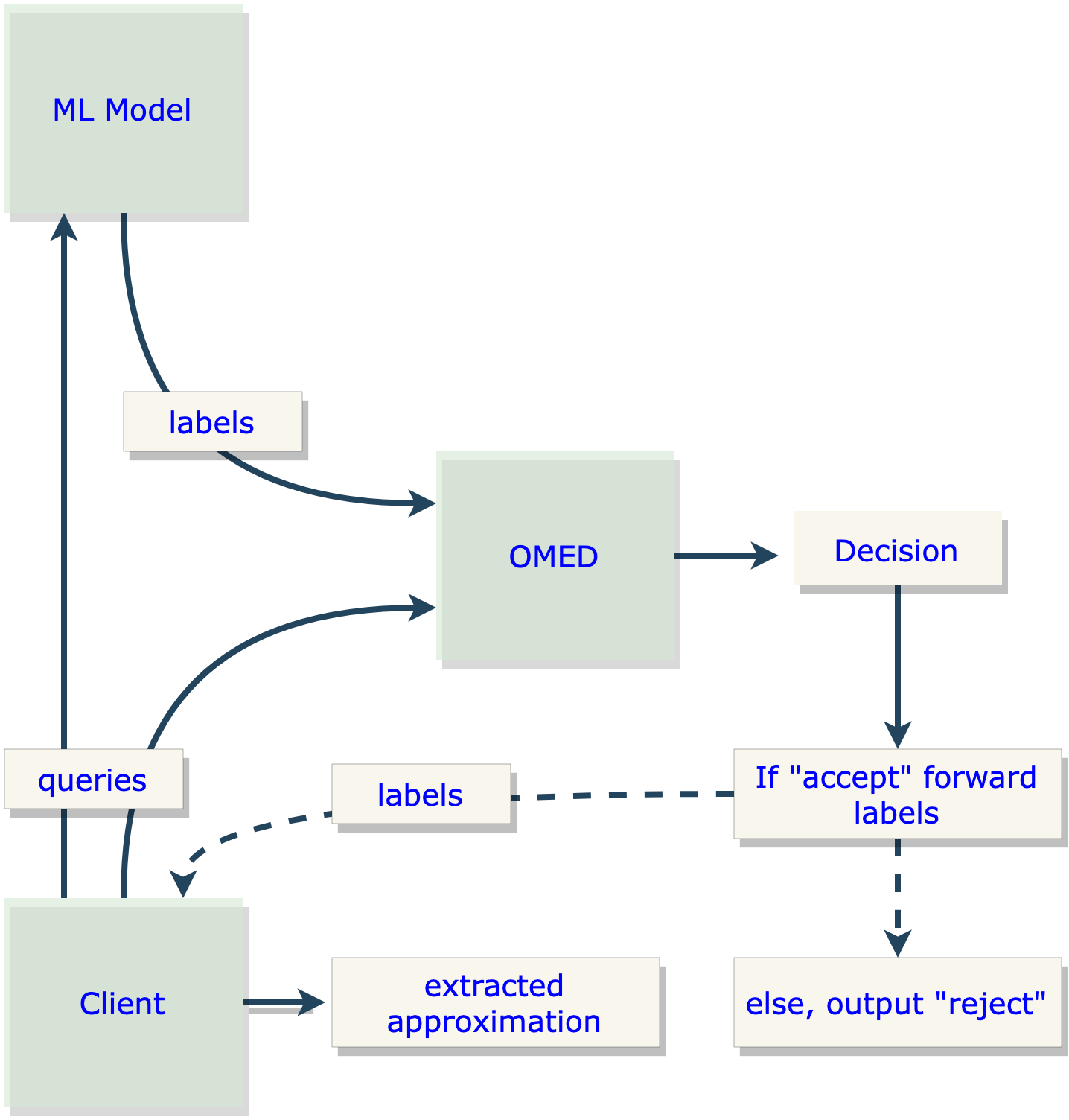
In other words, any client interacting with the ML model, whether adverse or benign, must query in accordance with an acceptable distribution. If they do not, the OMED will refuse service.
This raises the question: how should we determine the appropriate acceptable distributions? To date, these distributions have been chosen heuristically. For instance, in [JMAM19], an acceptable distribution is one where the distribution of Hamming distances between queries is normally distributed.
However, no formal definitions of security against model extraction have been proposed. Moreover, there has been limited formal work to understand the theoretical foundations of the observational defenses suggested in the literature. This gap was highlighted by Vinod Vaikuntanathan in his talk at the Privacy Preserving Machine Learning workshop at CRYPTO '21.
As a result, a "cat-and-mouse" dynamic has developed between attacks and defenses, with no satisfying guarantees being established for either side.
Towards provable security against model extraction
In my recent paper [Kar23], we explore whether OMEDs can provide satisfying provable guarantees of security. Inspired by modern Cryptography, where the security of protocols is mathematically guaranteed by the infeasibility of certain hard computational problems, we sought to apply similar principles to model extraction defenses.
But how do we define security against model extraction? An initial approach might consider leveraging zero-knowledge style security. Zero-knowledge proofs and their simulation-based security provide a framework where a client learns nothing about the ML model beyond what they could have learned prior to interacting with it. Essentially, the client gains no additional information about the model from their queries.
While this notion is appealing, it is overly restrictive. At a minimum, the client should be able to learn some information ("in good faith") from interacting with the model. Otherwise, clients may be deterred from using the model altogether, which is impractical for many applications.
Therefore, a revised security goal could be to ensure that a client learns nothing beyond what they could learn from a set of random queries to the model. This approach strikes a balance between the overly restrictive zero-knowledge guarantee and allowing complete query access to the model.
An implicit model of security for OMEDs
One of the key insights of my paper [Kar23] is that the notion of security implicitly underlying existing OMEDs aligns with this revised goal. While literature on OMEDs typically cites the objective of detecting model extraction attempts, the downstream effect is the confinement of client queries to specific, acceptable distributions by enforcing benign behavior. This enforcement assumes that any information a benign client can deduce from queries sampled from these distributions is considered secure.
To delve deeper, consider OMEDs for ML classifiers (which output predictions indicating whether an input belongs to a certain class). At first glance, the theory of statistical learning, particularly the Vapnik-Chervonenkis (VC) dimension framework, suggests that a number of samples proportional to the VC dimension suffices for Probably Approximately Correct (PAC) learning. This observation seems to undermine the potential of using the current security definitions to offer meaningful protection.
This is because an adversary with unbounded computational power could simply query the model according to an acceptable distribution sufficiently many times and apply a PAC-learning algorithm (which is guaranteed to exist by the fundamental theorem of statistical learning). The outcome would be a function that closely approximates the underlying ML model with high confidence.
What about computationally bounded adversaries?
However, this attack model does not account for the complexity of the implied model extraction attack. Depending on the model's complexity, such an attack may require superpolynomial query and computational resources. For many important classifier families (e.g., boolean decision trees), no polynomial-time PAC-learning algorithms are known, despite extensive efforts from the learning theory community. This remains true even when queries are restricted to uniformly distributed examples and the decision tree is "typical" rather than worst-case hard.
Overall, this provides evidence that the security model implicitly considered by observational defenses may effectively prevent unwanted model extraction by computationally bounded adversaries. The OMED constrains the adversary to interact with the query interface in a manner that mimics an acceptable distribution, from which learning the underlying model is computationally challenging.
Consequently, security against model extraction by computationally bounded adversaries can be provable in a complexity-theoretic sense, akin to Cryptography. One could aim to establish a reduction from polynomial-time PAC-learning to polynomial-time model extraction in the presence of observational defenses. In other words, a theorem could state that "any efficient algorithm capable of learning an approximation of a proprietary ML model while constrained by an observational defense would yield a PAC-learning algorithm, which is currently beyond all known techniques."
The contributions of [Kar23]
Having established that OMEDs could potentially provide a notion of provable security against computationally bounded adversaries, the next natural question addressed in [Kar23] is: Can OMEDs be efficiently implemented to withstand these efficient adversaries?
In [Kar23], I provide a negative answer to this question through the following approach:
- I formally define an abstraction of OMEDs by unifying the observational defense techniques proposed in the literature.
- I introduce the concepts of complete and sound OMEDs. Completeness guarantees that any benign client, defined as one interacting according to an acceptable distribution, is accepted and allowed to interact with the ML model's interface with high probability. Soundness ensures that any adverse client, defined as one not querying according to an acceptable distribution, is rejected with very high probability.
- Next, I present a method for generating provably effective and efficient attacks on the abstract defense, assuming that the defense operates in polynomial time and satisfies a basic form of provable completeness. This is achieved by connecting to the Covert Learning model from [CK21]. This connection implies an attack on any decision tree model protected by any OMED, under the standard cryptographic assumption known as Learning Parity with Noise (LPN).
- This attack represents the first provable and efficient attack on any large class of MEDs for a broad class of ML models!
- Finally, I extend an algorithm from [CK21] to operate in a more general setting. This extension produces an even more potent attack on efficient OMEDs, capable of handling OMEDs that satisfy a wider variety of completeness conditions.
Next time
In the next blog post, we will delve into the concept of Covert Learning and further elucidate its connection to model extraction.
References
- [BCK+22] Eric Binnendyk, Marco Carmosino, Antonina Kolokolova, Ramyaa Ramyaa, and Manuel Sabin. Learning with distributional inverters. In International Conference on Algorithmic Learning Theory, pages 90–106. PMLR, 2022.
- [BFKL93] Avrim Blum, Merrick Furst, Michael Kearns, and Richard J Lipton. Cryptographic primitives based on hard learning problems. In Annual International Cryptology Conference, pages 278–291. Springer, 1993.
- [CCG+20] Varun Chandrasekaran, Kamalika Chaudhuri, Irene Giacomelli, Somesh Jha, and Songbai Yan. Exploring connections between active learning and model extraction. In Proceedings of the 29th USENIX Security Symposium (USENIX Security 20), pages 1309–1326, 2020.
- [CJM20] Nicholas Carlini, Matthew Jagielski, and Ilya Mironov. Cryptanalytic extraction of neural network models. arXiv preprint arXiv:2003.04884, 2020.
- [CK21] Ran Canetti and Ari Karchmer. Covert learning: How to learn with an untrusted intermediary. In Theory of Cryptography Conference, pages 1–31. Springer, 2021.
- [CLP13] Kai-Min Chung, Edward Lui, and Rafael Pass. Can theories be tested? A cryptographic treatment of forecast testing. In Proceedings of the 4th Conference on Innovations in Theoretical Computer Science, pages 47–56, 2013.
- [DKLP22] Adam Dziedzic, Muhammad Ahmad Kaleem, Yu Shen Lu, and Nicolas Papernot. Increasing the cost of model extraction with calibrated proof of work. arXiv preprint arXiv:2201.09243, 2022.
- [GBDL+16] Ran Gilad-Bachrach, Nathan Dowlin, Kim Laine, Kristin Lauter, Michael Naehrig, and John Wernsing. Cryptonets: Applying neural networks to encrypted data with high throughput and accuracy. In International Conference on Machine Learning, pages 201–210. PMLR, 2016.
- [GL89] Oded Goldreich and Leonid A Levin. A hard-core predicate for all one-way functions. In Proceedings of the Twenty-First Annual ACM Symposium on Theory of Computing, pages 25–32, 1989.
- [GMR89] Shafi Goldwasser, Silvio Micali, and Charles Rackoff. The knowledge complexity of interactive proof systems. SIAM Journal on Computing, 18(1):186–208, 1989.
- [GPV08] Craig Gentry, Chris Peikert, and Vinod Vaikuntanathan. Trapdoors for hard lattices and new cryptographic constructions. In Proceedings of the 40th Annual ACM Symposium on Theory of Computing, pages 197–206, 2008.
- [JCB+20] Matthew Jagielski, Nicholas Carlini, David Berthelot, Alex Kurakin, and Nicolas Papernot. High accuracy and high fidelity extraction of neural networks. In Proceedings of the 29th USENIX Security Symposium (USENIX Security 20), pages 1345–1362, 2020.
- [JSMA19] Mika Juuti, Sebastian Szyller, Samuel Marchal, and N Asokan. Prada: protecting against DNN model stealing attacks. In 2019 IEEE European Symposium on Security and Privacy (EuroS&P), pages 512–527. IEEE, 2019.
- [Kar23] Ari Karchmer. Theoretical limits of provable security against model extraction by efficient observational defenses. In 2023 IEEE Conference on Secure and Trustworthy Machine Learning (SaTML), pages 605–621. IEEE, 2023.
- [KM93] Eyal Kushilevitz and Yishay Mansour. Learning decision trees using the Fourier spectrum. SIAM Journal on Computing, 22(6):1331–1348, 1993.
- [KMAM18] Manish Kesarwani, Bhaskar Mukhoty, Vijay Arya, and Sameep Mehta. Model extraction warning in MLaaS paradigm. In Proceedings of the 34th Annual Computer Security Applications Conference, pages 371–380, 2018.
- [KST09] Adam Tauman Kalai, Alex Samorodnitsky, and Shang-Hua Teng. Learning and smoothed analysis. In 2009 50th Annual IEEE Symposium on Foundations of Computer Science, pages 395–404. IEEE, 2009.
- [Nan21] Mikito Nanashima. A theory of heuristic learnability. In Conference on Learning Theory, pages 3483–3525. PMLR, 2021.
- [O’D14] Ryan O’Donnell. Analysis of Boolean functions. Cambridge University Press, 2014.
- [PGKS21] Soham Pal, Yash Gupta, Aditya Kanade, and Shirish Shevade. Stateful detection of model extraction attacks. arXiv preprint arXiv:2107.05166, 2021.
- [Pie12] Krzysztof Pietrzak. Cryptography from learning parity with noise. In International Conference on Current Trends in Theory and Practice of Computer Science, pages 99–114. Springer, 2012.
- [PMG+17] Nicolas Papernot, Patrick McDaniel, Ian Goodfellow, Somesh Jha, Z Berkay Celik, and Ananthram Swami. Practical black-box attacks against machine learning. In Proceedings of the 2017 ACM on Asia Conference on Computer and Communications Security, pages 506–519, 2017.
- [RWT+18] M Sadegh Riazi, Christian Weinert, Oleksandr Tkachenko, Ebrahim M Songhori, Thomas Schneider, and Farinaz Koushanfar. Chameleon: A hybrid secure computation framework for machine learning applications. In Proceedings of the 2018 IEEE Conference on Secure and Trustworthy Machine Learning (SaTML), pages 707–721, 2018.
- [TZJ+16] Florian Tramer, Fan Zhang, Ari Juels, Michael K Reiter, and Thomas Ristenpart. Stealing machine learning models via prediction APIs. In 25th USENIX Security Symposium (USENIX Security 16), pages 601–618, 2016.
- [Vai21] Vinod Vaikuntanathan. Secure computation and PPML: Progress and challenges. Video, 2021.
- [YZ16] Yu Yu and Jiang Zhang. Cryptography with auxiliary input and trapdoor from constant-noise LPN. In Annual International Cryptology Conference, pages 214–243. Springer, 2016.